If you’re new to this whole data visualization thing and get confused when people are talking about “logarithmic”, “CSV” or “legend” , then stick around, because we’ve been compiling a list of some of the most common words and phrases related to visualization.
Of course, learning the specifics of each of the topics we’ll be describing will take considerably more time, but hopefully this list will give you a good introduction.
You might not necessarily need each term in your day-to-day work, but it’s good to at least know what they are and what they’re referring to. They range from the most basic to the more technical, and should serve as your entry point for further research and investigation.
Notice that the list is not exhaustive, and will be continuously updated with time!
Before we jump into the detailed data visualization glossary itself, we have included a short description of different visualization categories and relationships – which is fundamentally important to understand when working with data visualization.
Table of Contents
Visualization categories and relationships
Standalone data points
Even if you just have one or two values to display, a visualization can be an effective way of getting this information across. A pie chart or gauge can be used to show a single percentage, or a bar chart can be a good way of showing how one value differs from a baseline figure.
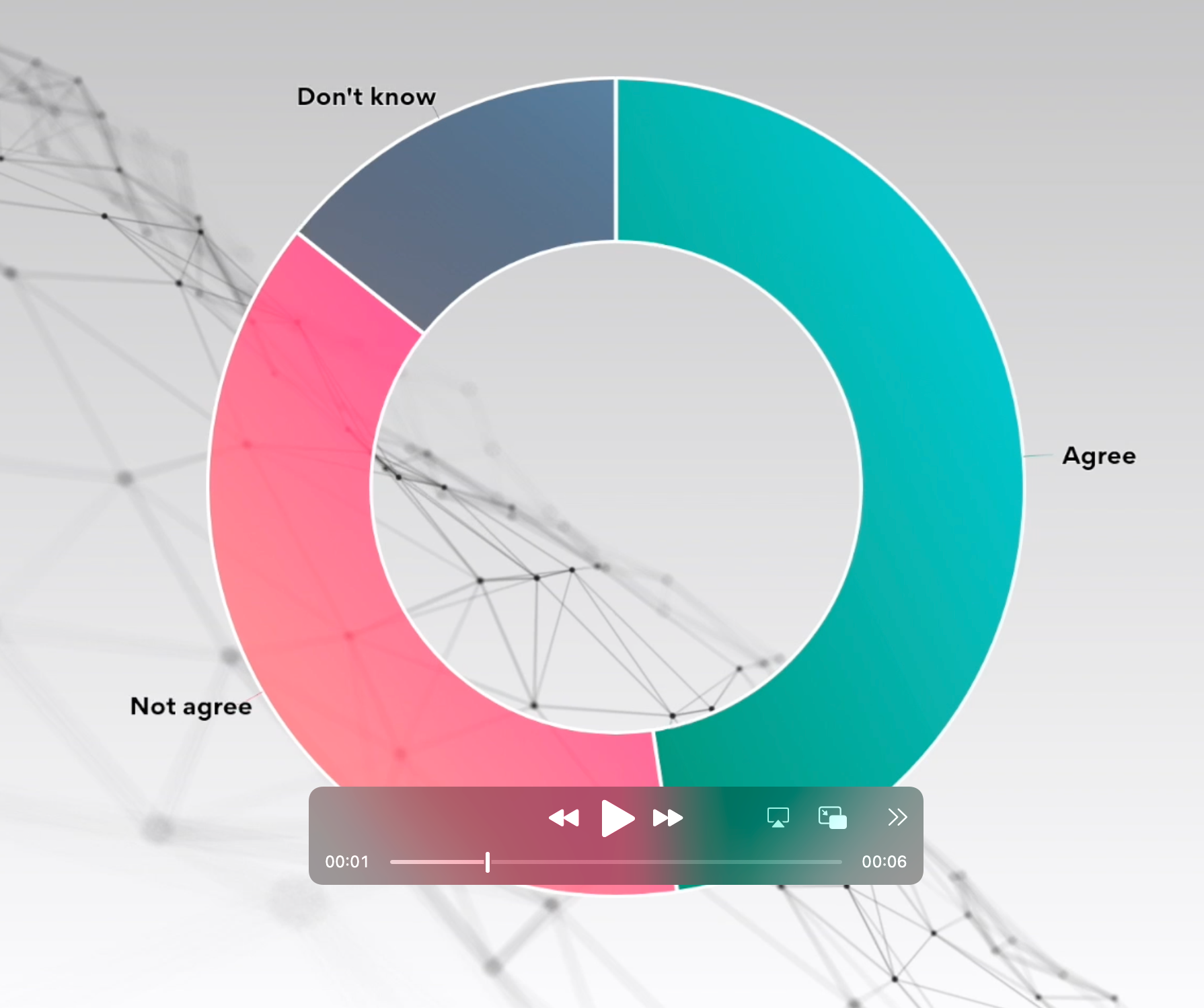
Part to whole comparison
Part-to-whole visualizations are used to show proportions or how something is divided up into component parts. This might include showing how a percentage or other value compares to its whole or showing how the whole is made up of different parts.
For simple comparisons, you might use a pie chart or donut chart. These are widely understood and work well to illustrate how a whole sum is divided into a small number of components.
Magnitude comparison
A simple way to compare the magnitude of multiple values is with a column or bar chart. These can be easily interpreted as it is much easier to compare the heights of adjacent columns than it is to visually determine which slice of a pie chart is larger.
Bar charts and column charts are very similar, they are just displayed in different orientations. Bars in a bar chart originate from the y-axis, columns in a column chart originate from the x-axis. The horizontal bar chart can usually accommodate more variables and longer variable names, so this might be preferred for larger data sets, but you can use whichever best fits your data and the available space.
The category axis is normally ordered in some way. You might choose to sort this by the magnitude of the value, alphabetically, or in some other way that makes sense for your data.
Change over time
If you want to illustrate how a variable changes over time, then you might choose to use a line, area or column chart. Time is usually plotted on the x-axis with the variable on the y-axis. If required, multiple series can be plotted on the same chart, allowing the variation of different variables to be compared.
Patterns/trends
Sometimes you may have a larger data set and you want to display all data points. This can be useful if you want your users to be able to appreciate the full dataset so they can see the overall patterns and trends as well as any outlying points.
A scatter graph allows you to plot large amounts of data against two axes and a bubble chart introduces a third dimension, allowing you to plot an additional variable by varying the point size in proportion to the magnitude of the variable.
Distribution
Sometimes you might want to illustrate some statistical features of your data set. Perhaps you want to show the range of your data values from minimum to maximum, or perhaps you want to show the mean or median values.
A histogram is a common way of illustrating the frequency distribution of a data set which can give useful insights. If you want to compare distributions across different data sets, then a box plot is a useful way of summarizing the range and statistical features for comparison.
Flows & processes
There are many different process diagrams to choose from to show the relationship between data flows. A Sankey diagram illustrates how data flows between nodes. For example, this might show how energy is used in a factory or how users move through a website. Dependency wheels are useful for showing multidirectional data flow, for example the import and export of goods between countries.
Simple processes can also be illustrated through funnel diagrams (which show data decrease through a process) or pyramids (used for hierarchical data). Time-based processes can also be shown on a timeline chart.
Geographical
If you have location-based data, you might choose to display this on a map. To simply mark locations (e.g. store addresses) you might use a point map. However, you can add an extra dimension by using a bubble map where the point size is adjusted in proportion to some variable (e.g. store revenue).
Choropleths are a type of map where a region is colored according to some variable (a rate or proportion). For example, a choropleth might be used to show crime rates in different states or the percentage of land use in different countries.
Visualization glossary
Annotations
Annotations are user-defined objects or shapes drawn on a chart, such as text boxes or highlight ranges. They can be used for a variety of presentational purposes, such as describing what is shown in the visualization or sharing information about intriguing findings. They can also be used to add directions or pose questions.
Axis
An axis can be either linear, categories, datetime or logarithmic. A distinguishing feature of the choice of axis is their support for formatting and different ways by which ticks are placed.
Cardinality
The number of elements in dimension (originally in a dataset). For instance, while coordinates have a high cardinality of however many elements is in the dataset – gender has a low cardinality of two, respectively.
Categorization
By grouping items, you can reduce cardinality when dealing with dimensions with high cardinality (higher than you need). For instance, you could create two categories instead of creating a graph for all age ranges: greater than or equal to 50 years and less than 50 years.
Comparable, uncomparable
Because numbers can be compared and sorted, numerical dimensions are comparable. However, some qualities cannot be compared; for example, you cannot say one thing is bigger (brighter, heavier, etc.) than another. One incomparable dimension is gender, for instance. Genders can be sorted alphabetically, but this makes no sense and the order may differ depending on the language.
Correlation
The degree to which one set of values is dependent upon another is determined by correlation. Values are positively correlated when they rise at the same rate. They are negatively correlated if one value from one set rises while the other falls. When a change in one set is unrelated to a change in the other, there is no correlation.
CSV
A delimited text file that uses commas to separate values is known as a comma-separated values (CSV) file. The file’s lines each contain a data record. One or more fields, separated by commas, make up each record. The name of this file format is derived from the fact that fields are separated by commas. Each line in a CSV file will typically contain the same number of fields if the data being stored is tabular (numbers and text).
Dataset
A dataset is a collection of data upon which a visualization is based. It is helpful to picture a dataset as a table with rows and columns that typically resides in a spreadsheet or database. The columns are the variables—details about the things—and the rows are the records—individual instances of things. It is possible to “see” the size, patterns, and relationships of datasets through visualization, which is difficult without it.
Data exploration
The part of the data science process where a scientist will ask basic questions that helps her understand the context of a data set. What you learn during the exploration phase will guide more in-depth analysis later. Further, it helps you recognize when a result might be surprising and warrant further investigation.
Data source
Visualizers will include the source of the data or information in the visualization when they want to demonstrate it. On occasion, it can be found at the bottom of the visualization or page, or close to the title. Sometimes the visualization is included with an article, in which case you can find it in the text that goes with it.
Data structure
A data structure refers to how data is organized in rows and columns in a spreadsheet. The same type of data must be entered in either the rows or columns.
GeoJSON
GeoJSON is an open standard format designed for representing simple geographical features, along with their non-spatial attributes. It is based on the JSON format.
The features include points (therefore addresses and locations), line strings (therefore streets, highways and boundaries), polygons (countries, provinces, tracts of land), and multi-part collections of these types. GeoJSON features need not represent entities of the physical world only; mobile routing and navigation apps, for example, might describe their service coverage using GeoJSON.
Interpolation
At its core, interpolation is a straightforward mathematical idea. One can logically estimate the value of the set at uncalculated points if there is a generally consistent trend across a set of data points. Investors and stock analysts frequently create a line chart with interpolated data points. These graphs, which are an essential component of technical analysis, assist users in visualizing changes in security prices.
JSON
JSON (JavaScript Object Notation) is an open standard file format and data interchange format that uses human-readable text to store and transmit data objects consisting of attribute–value pairs and arrays (or other serializable values). It is a common data format with diverse uses in electronic data interchange, including that of web applications with servers.
Logarithmic scale
A logarithmic scale (or log scale) is a way of displaying numerical data over a very wide range of values in a compact way—typically the largest numbers in the data are hundreds or even thousands of times larger than the smallest numbers. Such a scale is nonlinear: the numbers 10 and 20, and 60 and 70, are not the same distance apart on a log scale. Rather, the numbers 10 and 100, and 60 and 600 are equally spaced. Thus moving a unit of distance along the scale means the number has been multiplied by 10 (or some other fixed factor). Often exponential growth curves are displayed on a log scale, otherwise they would increase too quickly to fit within a small graph.
Linear scale
Contrary to a logarithmic scale chart, a linear scale, also known as an arithmetic chart, is a chart where the value between any two consecutive points on the line does not change no matter the location on the line. A linear scale is therefore always displaying numerical data with equal divisions for equal values. The value between any two consecutive points on the line does not change no matter the location on the line. A linear scale is also called a bar scale, scale bar or graphic scale.
Legend
Many charts will use various visual elements, such as colors, shapes, or sizes, to represent various data values. A legend or key explains the significance of these associations, making it easier for you to interpret the meaning of the chart.
Mean
(a.k.a Average, Expected Value) A calculation that gives us a sense of a “typical” value for a group of numbers. The mean is the sum of a list of values divided by the number of values in that list. It can be deceivingly used on its own, and in practice we use the mean with other statistical values to gain intuition about our data.
Median
In a set of values listed in order, the median is whatever value is in the middle. We often use the median along with the mean to judge if there are values that are unusually high or low in the set. This is an early hint to explore outliers.
Normalize
A set of data is said to be normalized when all of the values have been adjusted to fall within a common range. We normalize data sets to make comparisons easier and more meaningful. For instance, taking movie ratings from a bunch of different websites and adjusting them so they all fall on a scale of 0 to 100.
Outlier
An outlier or anomaly is someone or something that deviates from the norm within a given group, class, or category. This term refers to data rather than visualization, but we can identify outliers on plots individually.
Overplotting
When the data or labels in a data visualization overlap, it’s known as overplotting, which makes it difficult to distinguish between individual data points. When there are either a lot of data points or not enough unique values in the dataset, overplotting frequently happens.
Pivot
A pivot is a tabular data presentation that categorizes data into one or more groups. The table is filled with aggregate numerical calculations such as sums, averages, or counts that correspond to these categories. The labels for these categories are arranged across the top or down the side. A pivot table makes it simple to see a high-level aggregate view, break it down by different categories, and make comparisons in order to comprehend the reasons for the data and its sources.
Sample
Sample is the collection of data points we have access to. We use the sample to make inferences about a larger population. For instance, a political poll takes a sample of 1,000 British citizens to infer the opinions of all of Britain.
Scale
Scales are marks on a visualization that tell you the range of values of data that is presented. Scales are often presented as intervals (10, 20, 30 etc.) and will represent units of measurement, such as prices, distances, years, or percentages.
Standard deviation
The standard deviation of a set of values enables us to gauge their degree of dispersion. Because it is expressed in the same units as the values themselves, this statistic is more helpful than the variance. The standard deviation can be calculated mathematically as the square root of the variance of a set. The Greek letter sigma, σ, is frequently used to denote it.
Statistical significance
When we determine that a result most likely wasn’t the result of chance, we call it statistically significant. Although not always a sign of practical value, it is heavily used in surveys and statistical studies.
Variables
Variables are the various pieces of information that are stored about a “thing,” such as the name, date of birth, gender, and salary of an employee. Different types of variables exist, some of which are quantitative (such as salary), some of which are categorical (such as gender), while others are qualitative or text-based (e.g. name). A chart plots the relationship between different variables. For example, the bar chart to the right might show the number of staff (height of bar), by department (different clusters) broken down by gender (different colors).
In dataset-terms, the column header exists as the variable name, and the values under are the forms it takes.
Questions or ideas? Get in touch!
Would love to hear your thoughts, please get in touch!